Multiview 3D evaluation assumes that the images being scored are observations of one static 3D scene. This assumption can fail in NVS and sparse-view reconstruction: inputs or generated outputs may contain artifacts, outlier frames, repeated views, or noise, yet still receive high 3D consistency scores. Existing reference-based metrics require ground truth, while ground-truth-free metrics such as MEt3R depend on learned reconstruction backbones whose failure modes are poorly characterized. We study this reliability problem by comparing neural reconstruction priors with classical geometric verification. We introduce SysCON3D, a controlled robustness benchmark for multiview 3D consistency, and a parametric family that decomposes neural metrics into backbone, residual, and aggregation components. This family recovers MEt3R and yields variants up to 3× more robust. Our analysis shows that VGGT, MASt3R, DUSt3R, and Fast3R can hallucinate dense geometry and cross-view support for unrelated scenes, repeated images, and random noise. We introduce COLMAP-based metrics that use matches, registration, dense support, and reconstruction failure as failure-aware consistency signals. On real NVS outputs and a structured human study, these metrics achieve up to 4× higher correlation with human judgments than MEt3R.
We cast existing and new 3D-consistency metrics as a composition of backbone × residual × aggregation, and study distributional aggregations (e.g. MMD against a zero-error reference) that preserve information mean-based scores discard.
A controlled benchmark that injects 3D inconsistencies -- single outliers, patched regions, cross-scene mixtures, and Gaussian noise -- into multi-view sets, and reveals where current metrics rank inconsistent inputs above consistent ones.
Despite its age, COLMAP-based metrics are robust to noise/outliers and align up to 4× better with human ranking than MEt3R, suggesting that learned 3D backbones are not yet drop-in replacements for evaluation.
| Metric | Human-aligned | Robust | Scene-level | Interpretable |
|---|---|---|---|---|
| MEt3R | ✗ | ✗ | ✓ | ✗ |
| PRISM | ✓ | ✓ | ✗ | ✗ |
| Ours (MASt3R-W-IMQ) | ✓ | ✓ | ✓ | ✗ |
| Ours (COLMAP-based) | ✓ | ✓ | ✓ | ✓ |
We feed data-driven 3D reconstruction backbones inputs that have no shared 3D structure -- identical images, images from different scenes, and pure Gaussian noise -- and observe that they refuse to abstain from generating 3D geometry, returning dense, high-confidence point clouds anyway. Any consistency metric built on top inherits this behavior.

Choose a deterministic SysCON3D stress-test sample and compare the point clouds produced by MASt3R, DUSt3R, Fast3R, VGGT, and RobustVGGT. These are prerecorded GLB reconstructions from the benchmark, so the project page stays lightweight and does not run live GPU inference.
All views are deterministic Gaussian noise images with no 3D scene.
Drag any panel to orbit the 3D point cloud. Use scroll or pinch to zoom.
A model that knew when to abstain would return an empty or low-confidence cloud on inputs with no coherent scene. The learned backbones often return structured geometry anyway.
We probe each backbone with controlled cross-scene mixtures and Gaussian-noise inputs and track where the failure happens -- before features are even compared.
On the hardest cross-scene mixture (L3, where 89% of pairs are cross-scene), DUSt3R reports zero-overlap on only 26% of pairs. MASt3R, FASt3R, and VGGT still under-detect by 21, 48, and 18 pp respectively. The backbone declares overlap where geometrically there should be none.
Conditioning only on truly cross-scene pairs, DUSt3R falsely declares overlap on 64-77% across mixture levels; MASt3R is the most conservative at 18-26%. On Gaussian noise, MASt3R, DUSt3R, and VGGT hallucinate overlap on every pair; FASt3R on 22.7% of pairs.
Once the backbone declares two views overlap, cross-scene DINOv2 cosine residuals are only ~0.42-0.46 above same-scene residuals (MASt3R, DUSt3R), with standard deviations large enough to overlap. DINOv2 captures semantic similarity, not per-instance 3D identity, so spurious correspondences score nearly as low as real ones.
For the global backbones (FASt3R, VGGT) we measure the fraction of rendered pixels supported by points from a foreign scene. On L3 and full mixture roughly 40-50% of pixels come from wrong-scene points; on Gaussian noise VGGT's ghost mass climbs to 0.80 ± 0.10 -- the reconstruction is mostly invented.
The interactive gallery above shows representative precomputed reconstructions for these stress cases across K ∈ {3, 6}.
SysCON3D injects four families of 3D inconsistency into clean multi-view sets so we can measure how a metric ranks known inconsistent samples against clean ones. The deterministic benchmark manifests and image payload are available on HuggingFace; the interactive gallery above shows representative precomputed reconstructions.

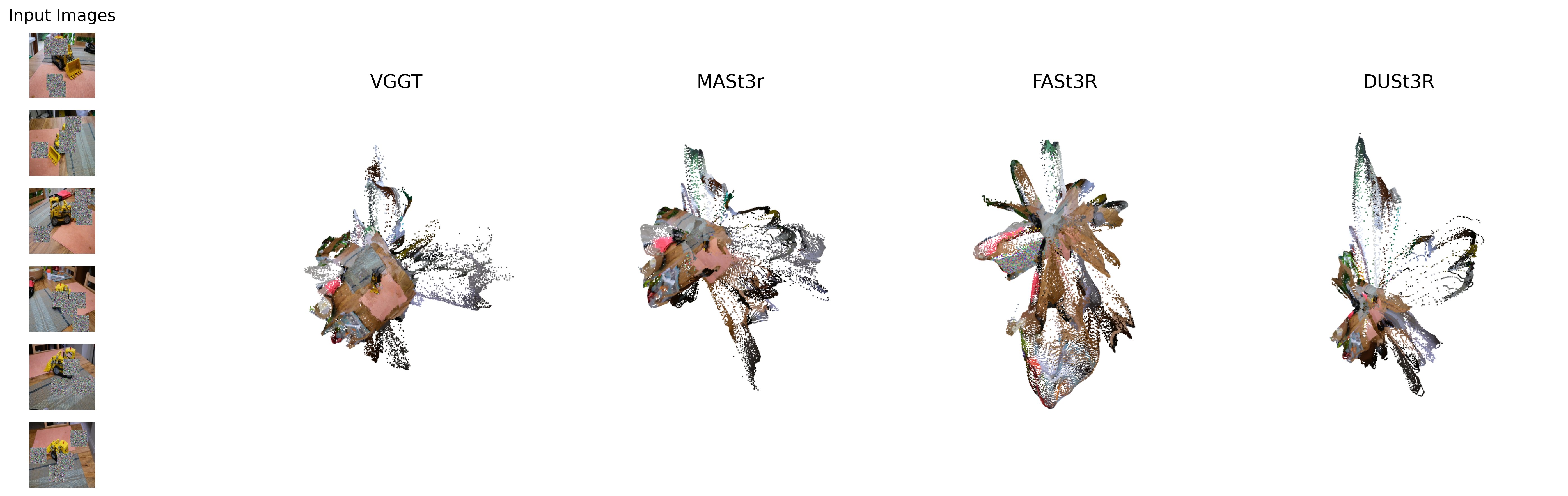


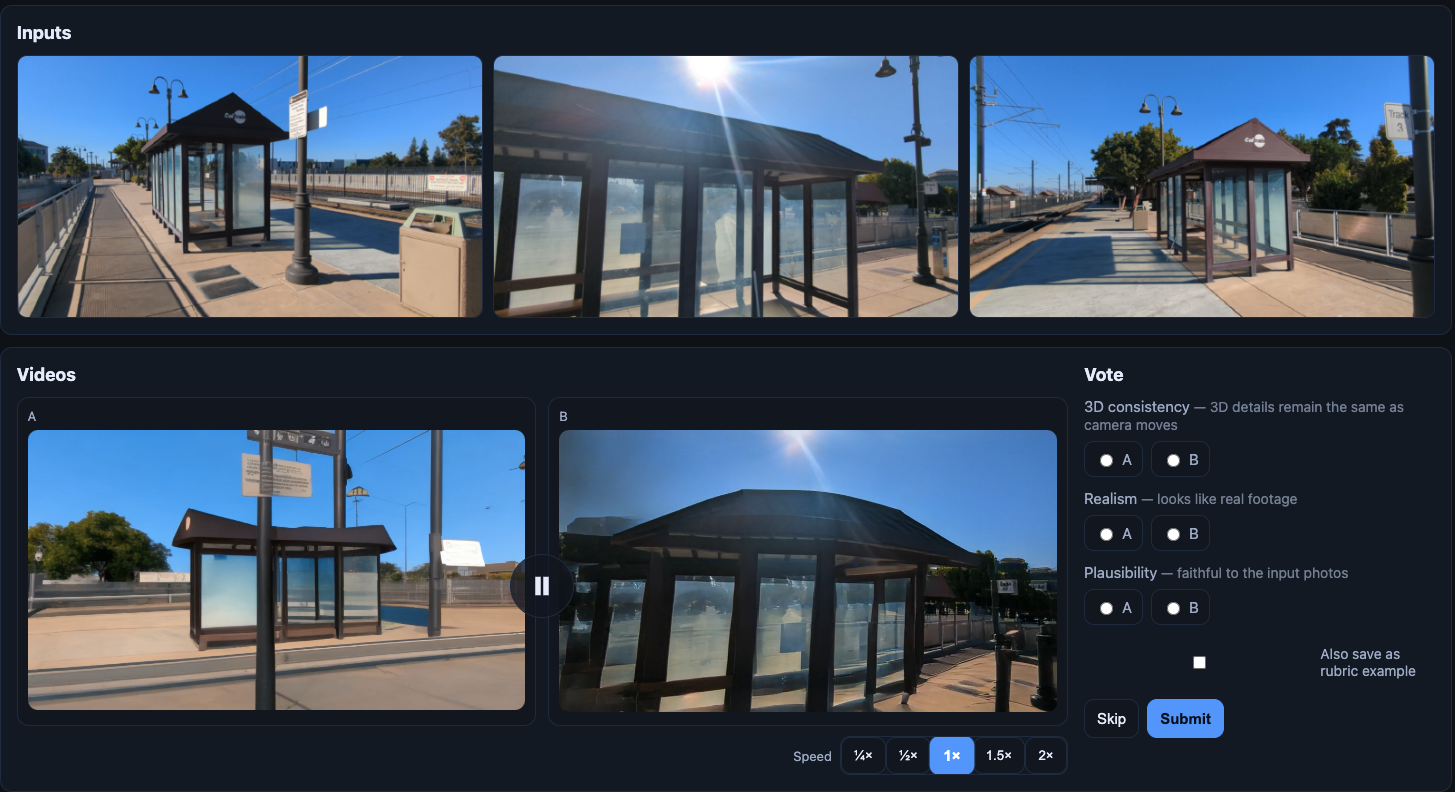
We ground all metric claims in a structured human study where evaluators view two NVS-rendered video clips side-by-side and rank them along three independent axes: 3D consistency, realism, and plausibility w.r.t. the input photos.
Each pair supports variable-speed playback and an optional free-text "why" prompt per axis, so judgments capture which dimension drove the preference rather than collapsing to a single scalar.
Sessions track a configurable target number of votes per evaluator, enabling multi-rater agreement analysis on top of the raw rankings.
@misc{paul2026viewssceneevaluatingmultiview,
title={Can These Views Be One Scene? Evaluating Multiview 3D Consistency when 3D Foundation Models Hallucinate},
author={Soumava Paul and Prakhar Kaushik and Alan Yuille},
year={2026},
eprint={2605.18754},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.18754},
}